Buf - A detailed introduction
TL;DR: Streaming data quality issues need better schemas with robust tooling. Bufstream delivers this with powerful policy checks and Protobuf performance. Join this workshop to learn more.
Note: Huge Thanks to Buf for sponsoring this blog. I have enjoyed exploring Buf and playing with it. I hope you also enjoy reading this introduction to Buf based on my research, observations and experiences.
Keeping bad data out of Kafka is a pain. All of us Kafka users have likely faced many production incidents due to bad events pushed to Kafka topics, resulting in unrecoverable errors.
But, what do we mean by bad data (or events) ?
Let’s take a concrete scenario, so we can create a clear picture of the problems.
Kafkaflix - A case study
Kafkaflix is a video streaming service that processes millions of “watch events” daily through their Kafka pipeline.
Following consumers consume these events for different use cases:
- Recommendations Engine: Suggested new videos based on watch history
- Billing Service: Calculated watch time for usage-based billing
- Analytics Dashboard: Generated viewing reports for content creators
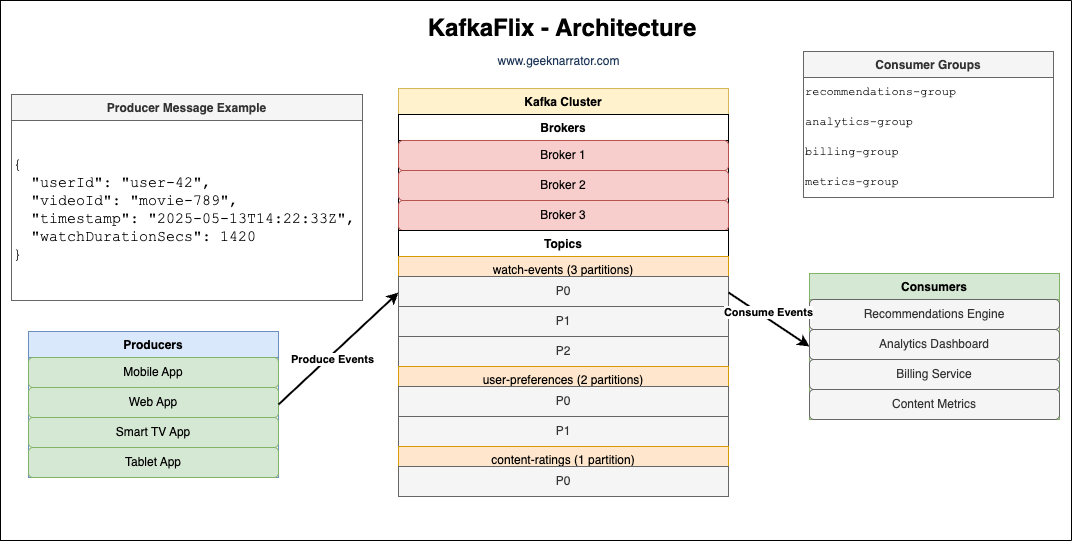
The team decided on a schema for a watch event and it looks like the following event:
{
"userId": "user-42",
"videoId": "movie-789",
"timestamp": "2025-05-13T14:22:33Z",
"watchDurationSecs": 1420,
"qualitySettings": {
"selectedQuality": "4K",
"qualityChanges": [
{
"timestamp": "2025-05-13T14:25:12Z",
"newQuality": "HD",
"reason": "BANDWIDTH_DECREASE"
},
{
"timestamp": "2025-05-13T14:32:45Z",
"newQuality": "4K",
"reason": "USER_SELECTION"
}
],
"avgBitrate": 15600
}
}All good so far—producers produce watch events, and consumers consume, parse and process the events. Processing may involve updating an external state like a database, a cache or an object storage.
As any growing business, Kafkaflix also has a roadmap filled with features and improvements. The product manager has decided to add a new feature called “Advanced Quality Insights” that would provide deeper analytics about streaming quality fluctuations to improve the overall viewing experience.
Business Requirements
- Track more granular metrics about each quality change
- Capture network conditions at the time of quality changes
- Record device performance impact during quality transitions
- Understand quality change impact on user engagement
- Enable correlation between quality events and infrastructure performance
The engineering team has proposed restructuring the qualityChanges field to include more detailed performance metrics. Proposed schema changes:
"qualityChanges": [
{
"id": "qc-123456",
"changeMetrics": {
"timestamp": "2025-05-13T14:25:12Z",
"previousQuality": "4K",
"newQuality": "HD"
},
"reason": {
"primaryFactor": "BANDWIDTH_DECREASE",
"bandwidthMbps": 8.2,
"stabilityScore": 0.65
},
"deviceImpact": {
"cpuUtilization": 0.45,
"memoryUtilization": 0.38,
"batteryDrainRate": 0.012
},
"userExperience": {
"bufferingDurationMs": 2340,
"rebufferingRatio": 0.03,
"playbackSmoothness": 0.88
}
}
]Schema evolution challenges
This schema change represents a significant restructuring of the qualityChanges field that would break existing consumers in several ways:
1. Path Changes to Critical Data
- Before: qualityChanges[0].timestamp
- After: qualityChanges[0].changeMetrics.timestamp
2. New Required Fields
- previousQuality is now required in the schema
- id field is required for tracking individual quality change events
3. Value Type Changes
- reason changed from a string to a complex object
4. Deeply Nested Structure
- Data that was previously at the top level is now nested several levels deep
This type of schema change, if not managed properly, would break existing consumers like the Recommendations Engine, Billing Service, and Analytics Dashboard, which rely on the previous schema structure. So how to solve this problem?
Using a Schema Registry for Kafkaflix
To address such schema evolution challenges in the Kafka ecosystem, schemas are typically shared via a schema registry, such as the Confluent Schema Registry or Glue Schema Registry. A schema registry acts as a central repository for schemas, associating them with topics.
Here’s how Kafkaflix could use a schema registry:
1. Schema Registration and Validation
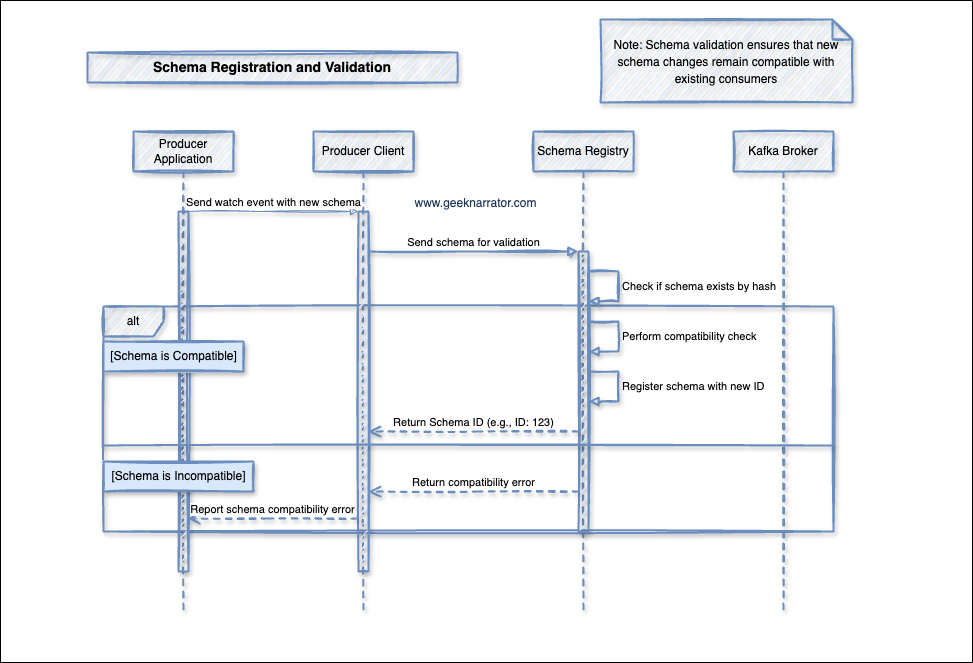
- Producer sends watch event with new schema to Producer Client
- Producer Client forwards schema for validation to Schema Registry
- Schema Registry performs three critical steps:
- Checks if schema exists by hash
- Performs compatibility check
- Registers schema with new ID if compatible
2. Message Serialization Process
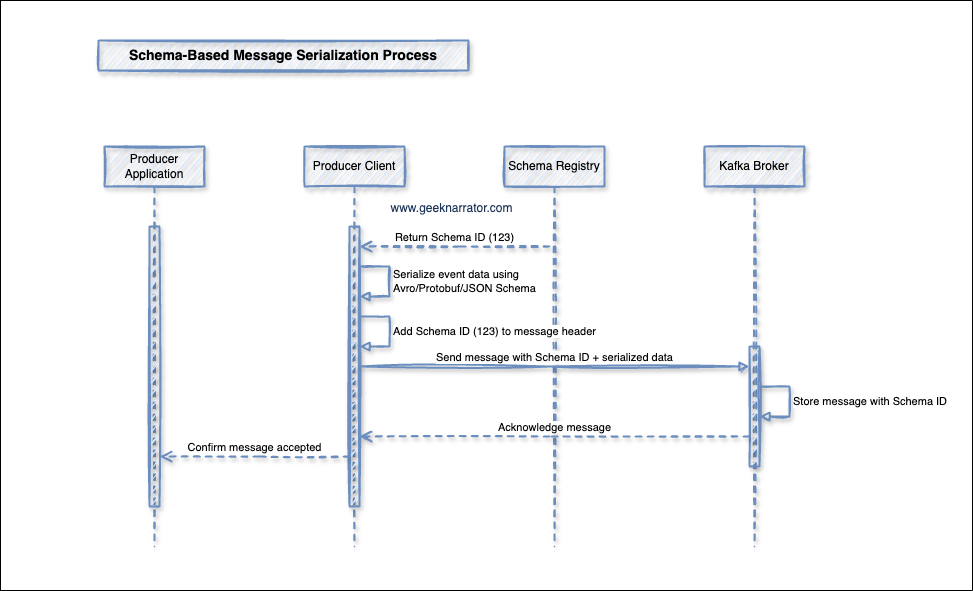
- Producer Client serializes the event data using the agreed schema format (Avro, Protobuf, or JSON Schema).
- Producer Client adds the Schema ID (e.g., 123) to the message header.
- Producer Client sends the message (Schema ID + serialized data) to the Kafka Broker.
- Kafka Broker stores the message with the Schema ID.
- Kafka Broker acknowledges message receipt back to the Producer Client.
- Producer Client confirms to the Producer Application that the message was accepted.
3. Message Consumption Process
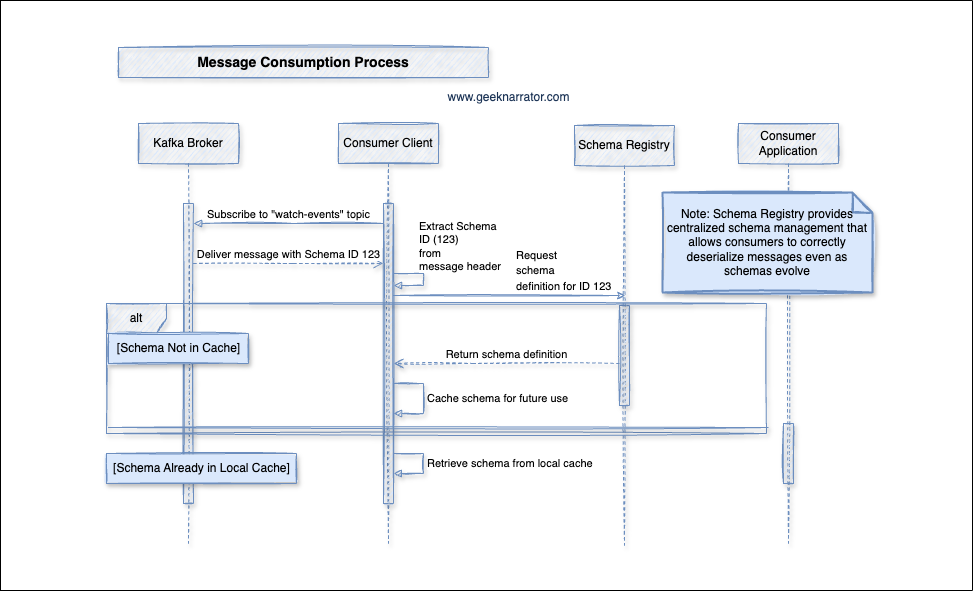
- Consumers subscribe to the Kafka topic (e.g., “watch-events”).
- Kafka Broker delivers a message to the Consumer Client, including the schema ID (e.g., 123) in the message header.
- Consumer Client extracts the schema ID from the message header.
- Schema lookup:
- If the schema for ID 123 is not in the local cache:
- The Consumer Client requests the schema definition for ID 123 from the Schema Registry.
- The Schema Registry returns the schema definition.
- The Consumer Client caches the schema for future use.
- If the schema for ID 123 is already in the local cache:
- The Consumer Client retrieves the schema from the local cache.
- If the schema for ID 123 is not in the local cache:
- Consumer Client uses the schema to deserialize the message payload.
- Deserialized message is delivered to the Consumer Application for processing.
- Schema Registry enables centralized schema management, ensuring that consumers can always fetch the correct schema for deserialization, even as schemas evolve.
4. Message Deserialization Process
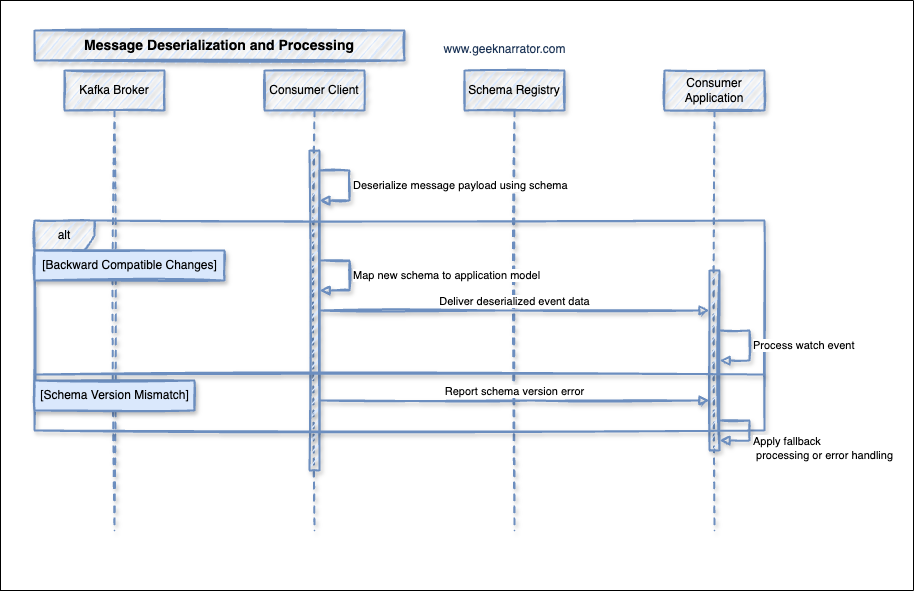
- Kafka Broker delivers messages to the Consumer Client.
- Consumer Client extracts schema ID from the message.
- The deserializer checks for the magic byte (typically byte 0).
- It then reads the schema ID (typically bytes 1-4).
- Schema lookup:
- If the schema is in the local cache, the Consumer Client uses it.
- If not, it requests the schema from Schema Registry using the schema ID.
- Deserialize message payload using schema (first step shown in diagram)
- The Consumer Client uses the schema to convert the binary payload into a structured object.
- Map new schema to application model (second step shown in diagram)
- The Consumer Client transforms the deserialized data to match the application’s expected format.
- For backward compatible changes:
- Deliver deserialized event data to the Consumer Application.
- Consumer Application processes watch events.
- For schema version mismatches:
- Report schema version error to the Consumer Application.
- Consumer Application applies fallback processing or error handling.
5. Schema Caching and Management
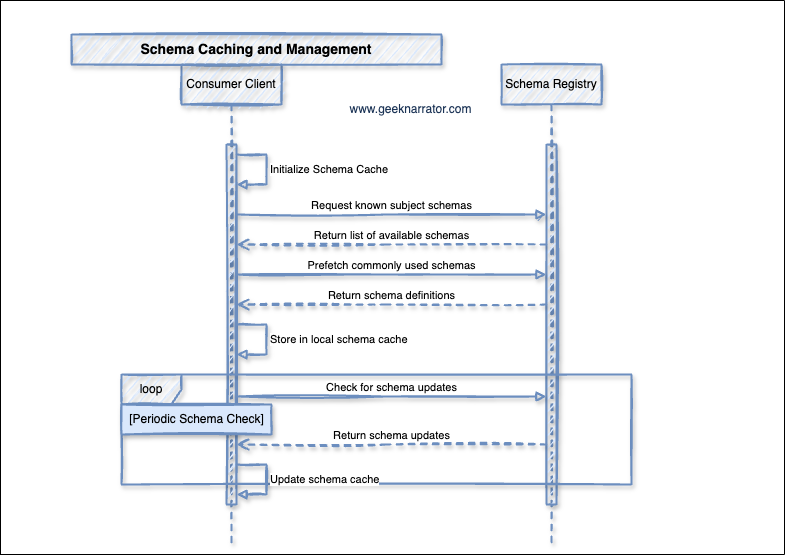
- Consumer Client creates an empty local schema cache.
- Consumer Client requests a list of available schemas from the Schema Registry.
- Schema Registry responds with metadata about available schemas.
- Consumer Client proactively requests full schema definitions for schemas it expects to use frequently.
- Schema Registry provides the requested schema definitions.
- Consumer Client stores the received schemas in its local cache for fast access.
- Consumer Client periodically polls the Schema Registry to check if any cached schemas have been updated.
- Schema Registry sends any updated schema definitions that have changed since last check.
- Consumer Client refreshes its local cache with the updated schemas.
This process ensures optimal performance by:
- Minimizing latency through local caching
- Keeping schema definitions current through periodic updates
- Reducing load on the Schema Registry through batch prefetching
All these steps help ensure that producers are using registered schemas and that some level of compatibility is maintained, ideally preventing consumers from encountering completely unknown schema structures.
Limitations of Traditional Schema Registries
- A good (and also bad thing) about Kafka is that its brokers are payload-agnostic and act as streamlined binary transport mechanisms.
- Good thing? Because it keeps the brokers simple and fast without additional overhead like schema validation.
- Bad thing? Because schema validation moves to the client side, making it “technically optional”. Producers may or may not choose to validate the schema before sending it. This can break the consumers (and their trust) anytime.
- New schemas are registered at runtime, which means any schema the producers have during the runtime can be registered, which doesn’t really sound safe as it might not have gone through a formal review process. Things changing at runtime sounds cool and fast, but can be very dangerous.
- Rule of thumb: The more checks you can get during the build/compile time the safer your schema evolution process will be.
- The compatibility checks performed by traditional schema registries are pretty “basic” and do not account for semantic properties. Basic checks are generally fine, but they don’t necessarily represent the real world use cases. ex. a field can be marked as required, but checking that its length is within a certain allowed range is what we need for real world use cases. Type safety is great, but there is always more we want in the real world.
- Specifically for Protobuf, the Confluent Schema Registry doesn’t check all the properties necessary to ensure true Protobuf compatibility.
Without proper schema governance, like a process that vets schemas before they can be registered, consumers cannot have confidence in the data quality. The problem of poor data quality in streaming data, which often results in broken downstream dashboards due to issues like missing or corrupted data, is attributed in part to this lack of guaranteed data quality at the source. And all these broken dashboards and data quality issues result in operational toil for developers and teams, resulting in decreased productivity and lost revenue.
Problems with JSON and Avro
JSON
Kafkaflix defines “watch event” schema in JSON format. While JSON is a universal language useful for human-readable representation, there are drawbacks, especially for high-throughput streaming data use cases like Kafkaflix’s millions of “watch events” daily. Why?
- JSON is inefficient as an interchange format because every key is consistently duplicated across messages as a long-form string. This increases message size and processing overhead, which is particularly problematic for large volumes of streaming data.
- Although tools like JSON Schema exist to add structure, JSON’s inherent “freeform nature” makes JSON Schema fall short as a modern schema language.
Avro
Avro is really powerful for big data use cases. It also has strong schema evolution mechanisms but not very well suited for production grade RPC use cases. The reason lies in the fact that readers cannot reliably decode messages without having access to the exact schema used to write the message.
From the Avro Spec:
”Binary encoded Avro data does not include type information or field names. The benefit is that the serialized data is small, but as a result a schema must always be used in order to read Avro data correctly. The best way to ensure that the schema is structurally identical to the one used to write the data is to use the exact same schema.”
and
”Avro-based remote procedure call (RPC) systems must also guarantee that remote recipients of data have a copy of the schema used to write that data.”
This is the primary reason why there aren’t any major examples of production grade RPC systems using Avro. Additionally, very few changes are both backward and forward compatible which makes the overall process difficult to manage, especially when the schema changes quite frequently.
It is important to note that other formats are also popularly used, but they have their own limitations and gaps.
Why is Protobuf a recommended choice for Schema Language?
Protobuf is an excellent choice for defining schemas across different tech stacks including streaming data. Use any stack, you will find a good, well maintained, battle tested library to use.
It is way more efficient as an interchange format than JSON, which is critical for high-throughput use cases ex. streaming. Protobuf and Avro are both “better when it comes to speed of serialization and deserialization” compared to JSON, with Protobuf generally leading in throughput benchmarks.
- Protobuf’s binary encoding format is “inherently more compact and space-efficient.”
- Protobuf “generally outperforms JSON in both serialization and deserialization tasks,” especially in high-performance, low-latency systems.
- Smaller Protobuf payloads mean less bandwidth and faster network transmission.
Avro and Protobuf are both really powerful, but based on my experience and observations, Protobuf is very well supported and generally more powerful across various stacks and use cases, especially talking about Schema Evolution.
With all the above context around why “Schema Evolution” without the pain is absolutely critical and why Protobuf is an ideal choice when talking about latency-sensitive, high-performance systems, I would love to introduce you to …drum roll…
Bufstream - Kafka replacement for the cloud era
Bufstream reimagines Apache Kafka for the cloud era, offering a complete drop-in replacement that clients report is 8x more cost-efficient to operate.
- Simplified Operations - While traditional Kafka typically requires multiple clusters and dedicated teams, Bufstream manages everything with a single cluster that elastically scales from zero to terabytes of data.
- Enhanced Data Quality - Built-in schema enforcement and real-time validation prevent bad data from entering your system.
- Seamless Integration - Works natively with Apache Iceberg and writes directly to object storage solutions like S3.
- Enterprise-Grade Security - Perfect for industries requiring strict compliance with no shared data or metadata.
- This solution deploys directly into your company’s own cloud environment, maintaining complete data sovereignty.
Schema-Driven Approach Using Bufstream
The team at Buf has been working hard to make Protobuf more accessible across various stacks.
Buf offers a different world with the Buf Schema Registry (BSR) and Bufstream, a Kafka replacement built with broker-side schema awareness. This approach directly addresses the problems of traditional schema registries and data quality.
Buf’s approach would look like this:
Schema Governance at Build-Time: The new, evolved “watch event” schema would be defined using Protobuf as shown below. Changes to the schema are managed like code changes, residing in source control. Before the schema can be used or even registered, it must pass stringent checks at build-time as part of the CI process.
Buf Schema Registry (BSR): The BSR serves as the central source of truth for schemas, but unlike traditional registries, schemas cannot appear unexpectedly by clients registering them at runtime. Schemas are only allowed to appear in the BSR through explicit pushes from source control after passing build-time checks.
Stringent Compatibility and Policy Checks: The BSR performs stringent breaking change and policy checks. This includes checking not only basic properties but also semantic properties via Protovalidate. Buf’s expertise in Protobuf ensures these compatibility checks are thorough. Any change deemed breaking or violating policies is blocked immediately at build-time, preventing bad schema changes from ever reaching the registry or being used in production. Schemas are treated as code and are code reviewed.
Build-Time Registration Flow: In Buf’s world, if the BSR has not seen a schema before, it returns an immediate error. This forces schemas to be registered and vetted before they are used by clients, eliminating the “recipe for disaster” from runtime registration.
Bufstream Broker-Side Schema Awareness: Bufstream is built from the ground up to understand the shape of the data traversing its topics. It’s more than just a simple data pipe.
Broker-Side Semantic Validation: Bufstream provides governed topics that enable semantic validation via Protovalidate directly on the producer API. When a producer sends a message using the new schema, Bufstream validates the data instance itself against the schema’s constraints (like ensuring a timestamp is present or a watch duration is within a valid range).
Blocking Bad Data: If a record doesn’t pass validation, the entire batch can be rejected or the offending record is sent to a Dead Letter Queue (DLQ) at the broker level.
Guaranteed Data Quality for Consumers: Because validation happens on the broker, consumers can rely on the knowledge that data within topics always matches its stated constraints. This solves the “tale as old as time” problem of bad data causing downstream dashboards to break days later, and prevents the Kafka team from being falsely blamed.
What would the schema evolution in KafkaFlix look like?
- All Protobuf schemas (e.g.,
watch_event.proto) are stored in Git. Changes require code reviews and CI checks before being pushed to the BSR. as shown below.
syntax = "proto3";
package kafkaflix.events;
import "buf/confluent/v1/extensions.proto";
import "google/protobuf/timestamp.proto";
message WatchEvent {
string user_id = 1;
string video_id = 2;
google.protobuf.Timestamp timestamp = 3;
int32 watch_duration_secs = 4;
// New fields added for Adaptive Streaming Quality
string device_type = 5 [(buf.confluent.v1.field_metadata) = { compatibility: "BACKWARD" }];
string connection_quality = 6;
int32 buffering_events = 7;
option (buf.confluent.v1.subject) = {
instance_name: "kafkaflix",
name: "watch-events-value" // Maps to Kafka topic `watch-events`
};
}- CI/CD Pipeline Enforcement: Before schemas reach the BSR, build-time checks block unsafe changes:
buf lint: Validates syntax and style.buf breaking: Detects backward-incompatible changes (e.g., adding required fields without defaults).- Policy checks: Enforce organizational rules (e.g., “new fields must be optional”).
- You can check the docs for commands here
- BSR as the Source of Truth: Schemas are pushed to BSR only after CI passes.
- The BSR auto-generates a Confluent Schema Registry (CSR) subject (watch-events-value) linked to the Protobuf message.
- Kafka producers/consumers reference the BSR-managed CSR endpoint for schema resolution.
- Safe Schema Evolution Workflow: When Kafkaflix adds deviceType, connectionQuality, and bufferingEvents:
- Developer updates
watch_event.proto:
- Developer updates
message WatchEvent {
// ... existing fields ...
optional string device_type = 5; // Marked optional for backward compatibility
optional string connection_quality = 6;
optional int32 buffering_events = 7;
}- CI runs
buf breaking --against main:- Verifies changes are backward-compatible with the existing schema in the BSR.
- Code review: Team validates the schema changes to match product requirements.
- Merge to main: Triggers a
buf pushto BSR, which:- Registers the new schema version in the CSR.
- Updates the Kafka topic’s schema subject (watch-events-value).
- Consumers upgrade:
- Updated consumers (using the new schema) start processing events with new fields.
- Old consumers ignore the new optional fields, avoiding deserialization errors.
This provides type safety, build time safety, semantic validation, power of Protobuf and reduces Schema Evolution pain.
Key advantages:
- No unexpected schema changes: Schemas evolve only through controlled code changes.
- Backward compatibility enforced: CI blocks breaking changes before they reach Kafka.
- Zero-downtime upgrades: Consumers handle new fields gracefully when ready.
Summary:
- Ensuring data quality in streaming data is extremely critical, but the current stack is painful and has many gaps.
- Protobuf is the recommended standard for schema language and Buf takes it to the next level with its powerful tooling and drop-in Kafka replacement Bufstream.
- Buf can help integrate policy check and schema validation in the build phase, which takes away a lot of painful surprises, making schema evolution easier.
Next Steps for you:
- Check out the links below and read more.
- Explore Bufstream’s docs and Quickstart as well as their GitHub Demo
- Buf is holding a workshop with their technical team on May 29, “How to bring schema-driven governance to streaming data.” Register here.
Cheers,
The GeekNarrator
Comments & Discussion